OpenAI 全新发布 o1 模型,我们正式迈入了下一个时代
作者:卡兹克
大半夜的,OpenAI抽象了整整快半年的新模型。
在没有任何预告下,正式登场。
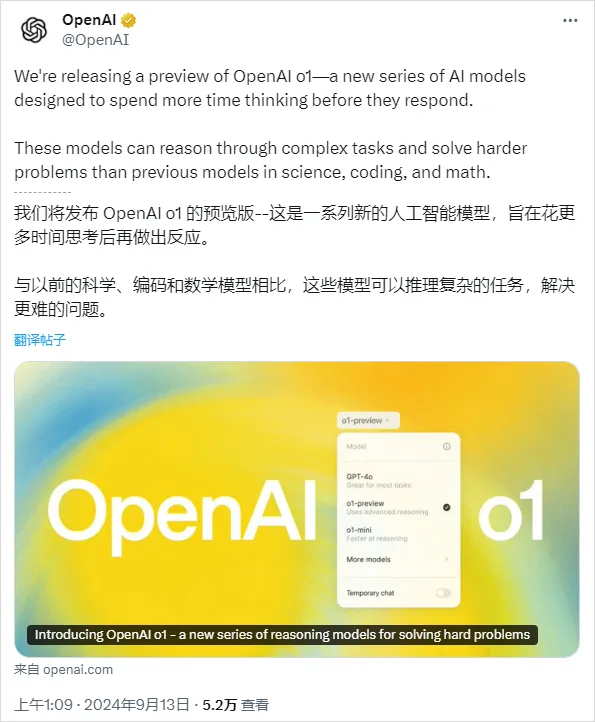
正式版名称不叫草莓,草莓只是内部的一个代号。他们的正式名字,叫:

为什么取名叫o1,OpenAI是这么说的:
For complex reasoning tasks this is a significant advancement and represents a new level of AI capability. Given this, we are resetting the counter back to 1 and naming this series OpenAI o1.
翻译过来是:
对于复杂推理任务来说,这是一个重要的进展,代表了人工智能能力的新水平。鉴于此,我们将计数器重置为 1,并将这一系列命名为 OpenAI o1。
这次模型的强悍,甚至让OpenAI不惜推掉了过去GPT系列的命名,重新起了一个o系列。
炸了,真的炸了。
我现在,头皮发麻,真的,这次OpenAI o1发布,也标志着,AI行业,正式进入了一个全新的纪元。
“我们通往AGI的路上,已经没有任何阻碍。
在逻辑和推理能力上,我直接先放图,你们就知道,这玩意有多离谱。
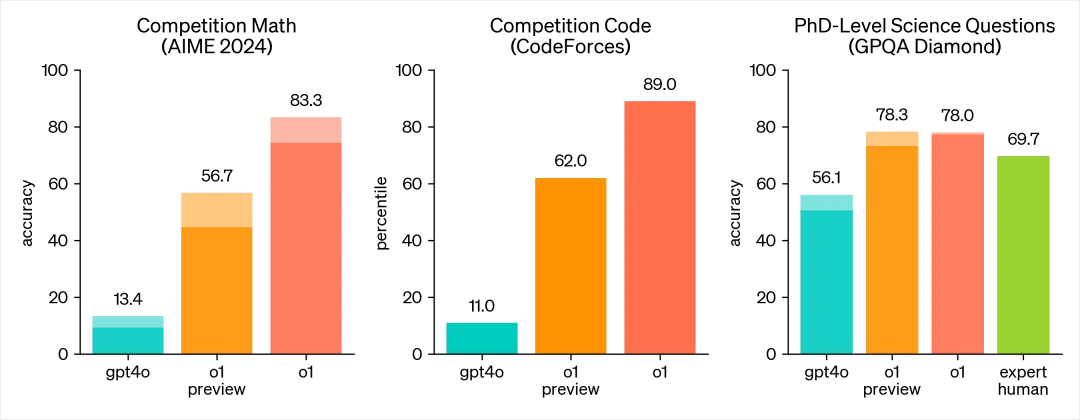
AIME 2024,一个高水平的数学竞赛,GPT4o准确率为13.4%,而这次的o1 预览版,是56.7%,还未发布的o1正式版,是83.3%。
代码竞赛,GPT4o准确率为11.0%,o1 预览版为62%,o1正式版,是89%。
而最牛逼的博士级科学问题 (GPQA Diamond),GPT4o是56.1,人类专家水平是69.7,o1达到了恐怖的78%。
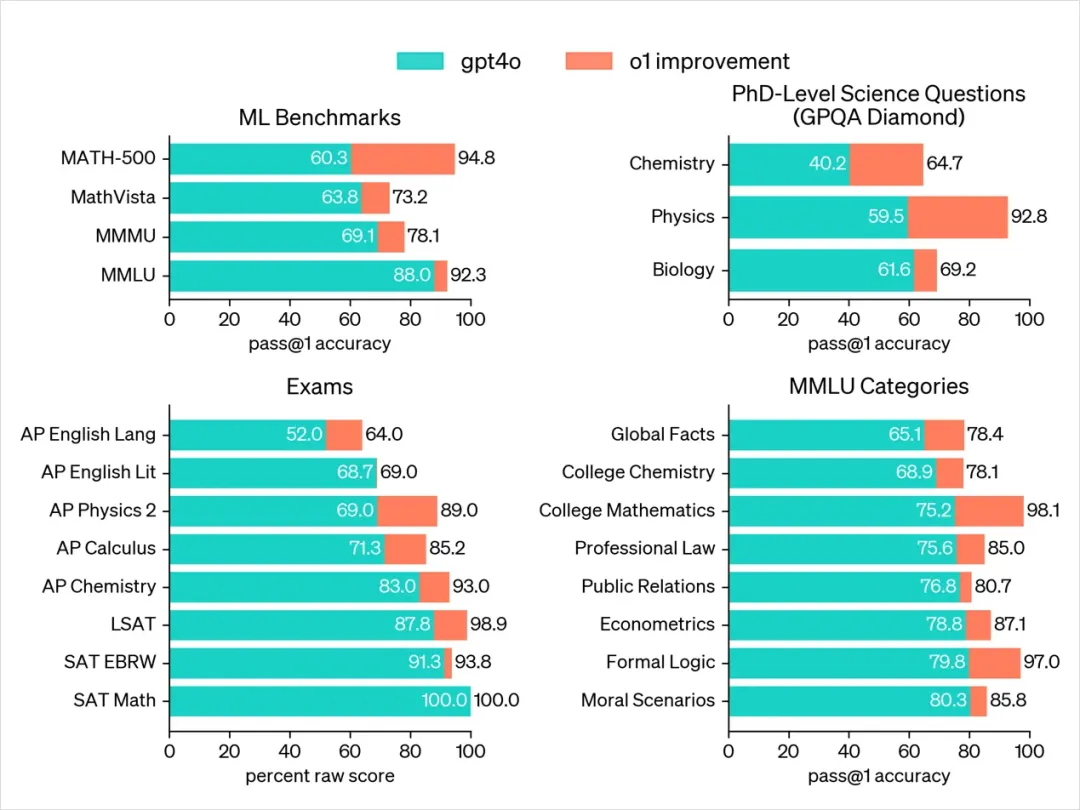
我让Claude翻译了一下o1的图,丑是丑了点,但是能看的懂每项数据意思就行。

什么叫全面碾压,这就是。
特别是在测试测试化学、物理和生物学专业知识的基准GPQA-diamond上,o1 的表现全面超过了人类博士专家,这也是有史以来,第一个获得此成就的模型。
而整个模型之所以达到如此成就,基石就是Self-play RL,不知道这个的可以去看我前两天的预测文章:新模型草莓到底是个啥?
通过Self-play RL,o1学会了磨练其思维链并完善所使用的策略。它学会了识别和纠正自己的错误。
它也学会了将复杂的步骤分解为更简单的步骤。
而且当当前的方法不起作用时,它也学会了尝试不同的方法。
他学会的这些,就是我们人类,最核心的思考方式:
- 申链财经
免责声明:投资有风险,入市须谨慎。本资讯不作为投资建议。